
导读 本文基于中科院计算所处理器芯片全国重点实验室编译与编程实验室赵家程老师的技术分享,从性能工程视角深度解析大模型推理的系统优化问题。作为一位深耕 AI 系统底层优化的专家,赵家程老师详细阐述了如何通过模型与系统的协同优化来提升大模型推理性能。文章涵盖了从算子优化、交互优化、并行策略到容错机制的全栈性能工程方法论,并重点介绍了 SigInfer 推理引擎在国产架构适配方面的实践经验。
分享嘉宾|赵家程 中国科学院计算技术研究所 中科院计算所副研究员
内容校对|郭慧敏
出品社区|DataFun
01
System for LLM:两条并行的研究道路

当前 AI 系统研究呈现出两个重要方向。第一个是 System for LLM,关注如何通过底层系统优化来提升大模型的训练和推理性能。第二个是 LLM for System,探索如何利用大模型能力驱动系统研究本身的进步。从基础编程框架层面来看,业界在 PyTorch、TensorFlow 等基础框架之上,已经形成了较为成熟的技术栈。在推理层面,vLLM、TensorRT 等推理系统成为主流选择,而在更高层次,各种大模型推理服务正在快速发展。
另一个新兴方向是 AI for Systems。大模型展现出的强大能力,正在驱动编译器、操作系统等底层系统研究的进步。无论从编译、算子、操作系统还是计算机科学的角度来看,这一领域都有广阔的探索空间。本次分享主要聚焦在如何通过与底层系统的深度结合来提升大模型推理性能这一方向。
02LLM 训练成本的巨大挑战 大模型训练的成本之巨大已经成为业界共识。以 BLOOM-176B 为例,其训练需要消耗惊人的计算资源和能源。Llama 系列模型的训练同样需要大规模 GPU 集群和长时间的计算投入。GPT-4 的技术报告也揭示了超大规模模型训练所面临的工程挑战。这些成本不仅体现在硬件投入上,还包括电力消耗、冷却系统、数据中心基础设施等多方面。正因如此,如何提高训练和推理效率成为 AI 系统研究的核心课题。03大模型的统一架构特征
大模型训练的成本之巨大已经成为业界共识。以 BLOOM-176B 为例,其训练需要消耗惊人的计算资源和能源。Llama 系列模型的训练同样需要大规模 GPU 集群和长时间的计算投入。GPT-4 的技术报告也揭示了超大规模模型训练所面临的工程挑战。这些成本不仅体现在硬件投入上,还包括电力消耗、冷却系统、数据中心基础设施等多方面。正因如此,如何提高训练和推理效率成为 AI 系统研究的核心课题。03大模型的统一架构特征 自 GPT 问世以来,当前主流大模型本质上都采用了 Decoder-Only 自回归 Transformer 架构。这种架构与早期 CV 领域各式各样的网络结构形成鲜明对比。在过去做计算机视觉的年代,网络结构千奇百怪,CNN 有各种变种,还有 LSTM 等各类网络,算子种类从未呈现收敛趋势。但自从 GPT 之后,大家使用的大语言模型本质上都是 Decoder-Only 的自回归结构。
自 GPT 问世以来,当前主流大模型本质上都采用了 Decoder-Only 自回归 Transformer 架构。这种架构与早期 CV 领域各式各样的网络结构形成鲜明对比。在过去做计算机视觉的年代,网络结构千奇百怪,CNN 有各种变种,还有 LSTM 等各类网络,算子种类从未呈现收敛趋势。但自从 GPT 之后,大家使用的大语言模型本质上都是 Decoder-Only 的自回归结构。自回归机制是指模型通过对序列中先前的输入进行测量来自动预测序列中的下一个分量,本质上就是一个 Next Token Prediction 任务。这种固定的结构特征为系统优化带来了新的机遇。当网络结构趋于统一,算子种类也相对收敛,优化工作可以更加聚焦。以 LLaMA2-7B 为例,模型包含 32 层 Transformer 结构,每层包括 QKV 投影矩阵、输出投影、前馈网络等组件,总参数量达到 6.48B。而 LLaMA2-70B 则扩展到 80 层,隐藏维度达到 8192,总参数量 68.45B。
Attention 机制中的因果掩码是自回归的关键特性,它让模型在预测当前 token 时无法看到未来的 token,保证了生成过程的自回归特性。大模型呈现出结构固定、运算单一、规模巨大三大核心特点,而核心运算主要集中在矩阵乘法和 Attention 两类算子上。这种统一性使得系统优化可以针对有限的算子进行深度打磨,而不是像以前那样需要处理成百上千种不同的算子。
04Scaling Law 驱动的模型演进 大模型的性能提升遵循 Scaling Law 这一第一性原理。模型性能随着模型规模、数据集大小和训练时间的增加而持续提升。这是驱动大模型发展的基本规律。与早期 CV 时代相比,模型体量发生了数量级的跃升。过去的 ResNet 等模型只有几 MB 到几百 MB,而现在一个被称为"精巧的小模型"都要 2B 参数起步。这种体量上的巨大变化对系统优化提出了全新的要求。05训练与推理的本质差异
大模型的性能提升遵循 Scaling Law 这一第一性原理。模型性能随着模型规模、数据集大小和训练时间的增加而持续提升。这是驱动大模型发展的基本规律。与早期 CV 时代相比,模型体量发生了数量级的跃升。过去的 ResNet 等模型只有几 MB 到几百 MB,而现在一个被称为"精巧的小模型"都要 2B 参数起步。这种体量上的巨大变化对系统优化提出了全新的要求。05训练与推理的本质差异
 虽然训练和推理都是针对同一个模型,但它们的计算特征却截然不同。训练包括 Forward 和 Backward 两个阶段,以 LLaMA2-13B 为例,Forward 阶段需要 159 TFLOP 的计算量,而 Backward 阶段则是 Forward 的两倍,达到 318 TFLOP。训练优化的目标是提升 MFU 即模型算力利用率,在 A100 GPU 上通常追求 50% 左右的 MFU。训练阶段面对的是相对定长且较长的上下文序列。
虽然训练和推理都是针对同一个模型,但它们的计算特征却截然不同。训练包括 Forward 和 Backward 两个阶段,以 LLaMA2-13B 为例,Forward 阶段需要 159 TFLOP 的计算量,而 Backward 阶段则是 Forward 的两倍,达到 318 TFLOP。训练优化的目标是提升 MFU 即模型算力利用率,在 A100 GPU 上通常追求 50% 左右的 MFU。训练阶段面对的是相对定长且较长的上下文序列。推理阶段则完全不同。推理仅需 Forward 过程,但 KV Cache 技术将推理分为两个截然不同的阶段。第一个是 Prefill 预填充阶段,处理输入 prompt,序列长度为 N,属于计算密集型。第二个是 Decode 解码阶段,逐 token 生成,序列长度仅为 1,属于访存密集型。以 LLaMA2-7B 的 Decode 阶段为例,典型的矩阵乘法规模中 M 维度仅为 1,这导致计算强度极低,性能瓶颈不在算力而在显存带宽。因此推理优化目标转向用户感知指标,比如首 token 延迟 TTFT、每 token 延迟 TPOT,以及带宽利用率 MBU,通常追求 80% 以上的带宽利用率。
06长上下文场景的 Attention 演进 长上下文场景下,Attention 机制面临巨大挑战。传统的 Multi-Head Attention 中,key 和 value 的每个 head 与 query 的每个 head一一对应,导致 KV Cache 存储和 Attention 访存压力巨大。为了解决这个问题,Grouped Query Attention 应运而生。在 GQA 中,key 和 value 的每个 head 对应一组 query 的 head,使得 KV Cache 压力下降 group_size 倍,已经成为主流选择。
长上下文场景下,Attention 机制面临巨大挑战。传统的 Multi-Head Attention 中,key 和 value 的每个 head 与 query 的每个 head一一对应,导致 KV Cache 存储和 Attention 访存压力巨大。为了解决这个问题,Grouped Query Attention 应运而生。在 GQA 中,key 和 value 的每个 head 对应一组 query 的 head,使得 KV Cache 压力下降 group_size 倍,已经成为主流选择。在 Prefill 阶段,输入序列长度为 N 且历史序列长度为 0 时,GEMM 计算量随 N 线性增长,但 Attention 计算量却随 N 的平方增长,同时中间变量的显存占用也在增加。而在 Decode 阶段,输入长度仅为 1 但历史序列长度为 N,此时 KV Cache 显存占用随 N 线性增长,Attention 的计算和访存也随 N 线性增长。这种计算特征的差异要求系统在不同阶段采用不同的优化策略。
07全栈性能工程的优化目标 针对训练和推理的不同特征,全栈性能工程设定了清晰的优化目标。以 LLaMA3 在 A100 GPU 上的表现为例,A100 具有 312T 的算力和 2TB 的带宽,训练的目标是将 MFU 提升到 50% 左右,而推理的目标则是将 MBU 提升到 80% 左右。要实现这些目标,需要从多个层面协同优化,打通从算法到硬件的完整链路。08CPU-GPU 异构系统的交互挑战
针对训练和推理的不同特征,全栈性能工程设定了清晰的优化目标。以 LLaMA3 在 A100 GPU 上的表现为例,A100 具有 312T 的算力和 2TB 的带宽,训练的目标是将 MFU 提升到 50% 左右,而推理的目标则是将 MBU 提升到 80% 左右。要实现这些目标,需要从多个层面协同优化,打通从算法到硬件的完整链路。08CPU-GPU 异构系统的交互挑战 现代 AI 计算系统是典型的 CPU-GPU 异构系统。一个标准的 8 卡 A100 服务器通常包含两个 NUMA node,每个 node 下挂载 PCIe switch,通过 PCIe 将 CPU 与 4 个 A100 连接起来。这 8 个 A100 之间通过 NVLink 互联形成一个计算集群。对于跨机通信,还需要通过 PCIe 连接到网卡,再通过网络与其他机器互联。
现代 AI 计算系统是典型的 CPU-GPU 异构系统。一个标准的 8 卡 A100 服务器通常包含两个 NUMA node,每个 node 下挂载 PCIe switch,通过 PCIe 将 CPU 与 4 个 A100 连接起来。这 8 个 A100 之间通过 NVLink 互联形成一个计算集群。对于跨机通信,还需要通过 PCIe 连接到网卡,再通过网络与其他机器互联。这个系统包含几个核心组件。首先是 CPU 负责控制,其次是每个人都想打满的 GPU 负责计算,最后是用于多机通信的网卡 NIC。计算最终要发生在 GPU 上,但数据可能需要从 CPU 内存传输过来,模型参数需要与远端机器通过网卡交换。每一次跨越芯片边界的交互都存在潜在的性能瓶颈。比如 CPU 到 GPU 需要走 PCIe,GPU 到网卡也需要走 PCIe。跨节点的 GPU 通信更加复杂,数据需要经过 PCIe switch、网卡,再到另一台机器的网卡和 PCIe,最终才能到达目标 GPU。
从优化角度来看,可以分为两个维度。控制面优化的核心目标是让 GPU 一直忙起来,通过异步执行、任务调度优化、多流并发等手段,在传输数据或等待通信时让 GPU 还能干其他活。数据面优化则关注让 GPU 在忙的时候更有效率,即提升算子本身的计算效率、优化访存模式、充分利用算力资源。
09GPU 算力的构成与利用难题 以 A100 GPU 为例来看算力的来源。A100 包含 108 个 SM 即流式多处理器,每个 SM 包含 4 个 Tensor Core,每个 Tensor Core 支持 16×8×16 的矩阵乘法,吞吐为 8 个 cycles。通过公式计算可以得出张量算力约为 311.8 TFLOPS。算力的计算公式本质上是并行单元数量乘以平均每 Cycle 运算再乘以频率。
以 A100 GPU 为例来看算力的来源。A100 包含 108 个 SM 即流式多处理器,每个 SM 包含 4 个 Tensor Core,每个 Tensor Core 支持 16×8×16 的矩阵乘法,吞吐为 8 个 cycles。通过公式计算可以得出张量算力约为 311.8 TFLOPS。算力的计算公式本质上是并行单元数量乘以平均每 Cycle 运算再乘以频率。从优化难度来看,频率提升是最容易的,因为不需要做任何代码改动就能享受到性能提升,这是所谓的 Free Lunch。并行单元数量的利用相对容易,通过合理的并行策略就能实现。但平均每 Cycle 运算的利用是最困难的,尤其当 GPU 引入高算力的 Tensor Core 之后,如何充分利用每个 Cycle 的运算能力成为最大挑战。
10矩阵算子的动态形状难题 矩阵乘法是大模型的基础算子。使用 cuBLAS 库在 A100 上的性能测试揭示了一个关键问题,那就是不同形状的 GEMM 性能差异可能非常巨大。在 Decode 阶段,矩阵的 M 维度随用户输入长度动态变化。用户输入一个 token 长度就是 1,输入两个 token 长度就是 2,这直接反映到底层就是 M×N×K 的矩阵乘法中 M 维度的变化。
矩阵乘法是大模型的基础算子。使用 cuBLAS 库在 A100 上的性能测试揭示了一个关键问题,那就是不同形状的 GEMM 性能差异可能非常巨大。在 Decode 阶段,矩阵的 M 维度随用户输入长度动态变化。用户输入一个 token 长度就是 1,输入两个 token 长度就是 2,这直接反映到底层就是 M×N×K 的矩阵乘法中 M 维度的变化。通过实际测试发现,即使两个矩阵的计算密度都处于 Compute Bound 区域,实际性能也可能相差 10 倍以上。一个可能只有 20 多 TFLOPS,另一个却能达到 260 多 TFLOPS。这说明对于动态形状场景,矩阵乘法优化本来就是一个非常具有挑战性的任务。如果最基础的矩阵乘法都做不好,端到端的效率不可能更高。因此如何在动态场景下提升矩阵乘法的算力利用率,成为推理系统优化的基础性难题。
11Flash Attention 的算法创新 Flash Attention 通过算法与系统的协同设计实现了 Attention 计算的革命性优化。它的核心思想是融合 Attention 阶段的所有计算,解决矩阵乘与 Softmax 规约操作的融合问题。传统方法需要将 Q×K 转置的中间结果写回 Global Memory 再重新读入,而 Flash Attention 通过 Online Softmax 技术在片上完成所有计算,消除了中间结果的显存访问开销。这一优化显著降低了显存访问量,提升了计算效率。12Paged Attention 的显存管理创新
Flash Attention 通过算法与系统的协同设计实现了 Attention 计算的革命性优化。它的核心思想是融合 Attention 阶段的所有计算,解决矩阵乘与 Softmax 规约操作的融合问题。传统方法需要将 Q×K 转置的中间结果写回 Global Memory 再重新读入,而 Flash Attention 通过 Online Softmax 技术在片上完成所有计算,消除了中间结果的显存访问开销。这一优化显著降低了显存访问量,提升了计算效率。12Paged Attention 的显存管理创新 传统 KV Cache 分配存在两大问题,一是碎片化即预分配小于实际使用,二是过度保留即预分配大于实际使用。Paged Attention 借鉴操作系统内存管理中的 Page 抽象,用 Page 动态管理 KV Cache 的显存分配情况。这一创新来自 vLLM 项目,已经成为现代推理系统的标配技术。但随之而来的新挑战是,需要为不同的异构芯片实现 Flash Attention 和 Paged Attention 的组合优化,这要求为每种硬件架构都实现高性能的 Paged Attention 算子。13软件栈的层次结构
传统 KV Cache 分配存在两大问题,一是碎片化即预分配小于实际使用,二是过度保留即预分配大于实际使用。Paged Attention 借鉴操作系统内存管理中的 Page 抽象,用 Page 动态管理 KV Cache 的显存分配情况。这一创新来自 vLLM 项目,已经成为现代推理系统的标配技术。但随之而来的新挑战是,需要为不同的异构芯片实现 Flash Attention 和 Paged Attention 的组合优化,这要求为每种硬件架构都实现高性能的 Paged Attention 算子。13软件栈的层次结构 完整的 AI 软件栈包括多个层次。应用层包括 PyTorch、JAX、TensorFlow 等训练框架,配合 DeepSpeed、Megatron 等扩展工具,以及 vLLM、TensorRT 等推理系统,还有 MLIR、Dynamo 等 AI 编译器。中间层包括 NCCL、HCCL 等通信库,cuBLAS、cuDNN 等算子库,以及 Triton 等领域专用语言。底层则包括 Runtime 运行时管理、用户态驱动 UMD、内核态驱动 KMD、PTX 等虚拟指令集,以及 SASS、GCN 等汇编层。整个栈的优化需要覆盖控制面的任务调度和数据面的算子执行两个维度。14交互墙带来的性能瓶颈
完整的 AI 软件栈包括多个层次。应用层包括 PyTorch、JAX、TensorFlow 等训练框架,配合 DeepSpeed、Megatron 等扩展工具,以及 vLLM、TensorRT 等推理系统,还有 MLIR、Dynamo 等 AI 编译器。中间层包括 NCCL、HCCL 等通信库,cuBLAS、cuDNN 等算子库,以及 Triton 等领域专用语言。底层则包括 Runtime 运行时管理、用户态驱动 UMD、内核态驱动 KMD、PTX 等虚拟指令集,以及 SASS、GCN 等汇编层。整个栈的优化需要覆盖控制面的任务调度和数据面的算子执行两个维度。14交互墙带来的性能瓶颈 任务下发和调度的开销直接影响系统性能。测试显示,Launch 一个什么都不做的 NOP Kernel 所需的时间,在 CUDA 和 ROCm 上约为 2 到 3 微秒,而在某些加速卡上可能达到 5 到 10 微秒,甚至 20 到 60 微秒。任务调度开销方面,CUDA 可以做到小于1微秒,而某些加速卡需要 5 到 10 微秒。当一个 Kernel 的执行时间仅为 5 微秒时,如果下发开销就达到 10 微秒,系统效率将大打折扣。这种"交互墙"成为制约加速器算力发挥的关键瓶颈。
任务下发和调度的开销直接影响系统性能。测试显示,Launch 一个什么都不做的 NOP Kernel 所需的时间,在 CUDA 和 ROCm 上约为 2 到 3 微秒,而在某些加速卡上可能达到 5 到 10 微秒,甚至 20 到 60 微秒。任务调度开销方面,CUDA 可以做到小于1微秒,而某些加速卡需要 5 到 10 微秒。当一个 Kernel 的执行时间仅为 5 微秒时,如果下发开销就达到 10 微秒,系统效率将大打折扣。这种"交互墙"成为制约加速器算力发挥的关键瓶颈。从底层机制来看,CPU 和 GPU 之间的交互涉及多个层次。以 AMD GPU 为例,它采用开源程度较高的架构。GPU 片上除了计算单元外,还有一个 Command Processor 负责控制。这个 CP 本质上运行着一个 firmware 代码,通常是 ARM 或 RISC-V 核心。当 CPU 给 GPU 下发任务时,需要通过 UMD 用户态驱动将任务信息写入 CPU 和 GPU 都可见的内存空间,然后 CP 不断轮询队列指针,看到新任务后将其分发到计算单元执行。这整个流程都需要时间,而随着计算能力越来越快,这个交互流程对端到端效率的影响就越来越大。
15并行策略的选择与权衡
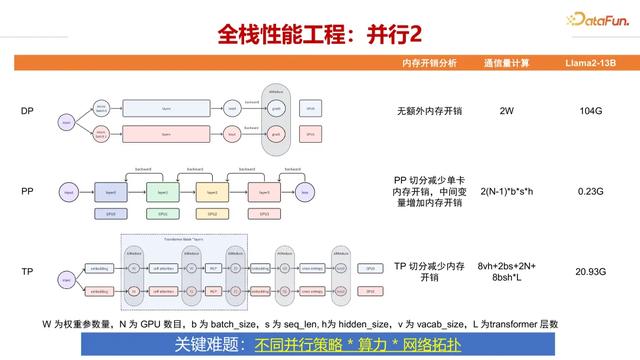
大模型训练和推理需要多种并行策略。数据并行 DP 将数据分配到不同 GPU 上,每个 GPU 保存完整模型,通信量为两倍权重参数量,没有额外内存开销。流水线并行 PP 将模型按层切分到不同 GPU上,减少了单卡内存开销但增加了中间变量的内存开销,通信量取决于节点数、batch 大小和序列长度。张量并行 TP 将单层内的张量切分到不同 GPU 上,能够减少内存开销。
以 LLaMA2-13B 为例,DP 的内存开销约为 104GB,TP 开销仅为 0.23GB,而 PP 开销约为 20.93GB。不同并行策略在内存占用和通信开销上各有特点,如何根据具体的算力、网络拓扑选择最优的并行策略组合,是一个需要深入研究的问题。
16通信优化的延迟与吞吐平衡推理场景下的数据量通常在几十 KB 级别,远小于训练场景。因此需要采用更偏向于低延迟的通信算法,而不是单纯追求极致吞吐量。这与训练场景有本质区别,需要针对性地优化通信策略。
17容错机制的必要性 随着推理系统规模的扩大,容错变得不可忽视。为了追求更好的性能,推理实例往往需要使用大规模的张量并行,可能包含 128 甚至 256 个加速卡。卡数越多,单卡故障率累积起来就越不容忽视。一旦其中一个卡出现故障,整个通信域就需要重建,导致系统不可用。
随着推理系统规模的扩大,容错变得不可忽视。为了追求更好的性能,推理实例往往需要使用大规模的张量并行,可能包含 128 甚至 256 个加速卡。卡数越多,单卡故障率累积起来就越不容忽视。一旦其中一个卡出现故障,整个通信域就需要重建,导致系统不可用。容错需要解决三个关键问题。首先是如何快速发现错误,其次是发现错误后如何进行故障隔离,最后是隔离后如何快速恢复服务。这些问题以前主要在训练系统中研究,但现在推理系统同样需要高效的容错方法和低开销的容错机制,以保证系统的可用性和稳定性。
18SigInfer 推理引擎的架构设计 SigInfer 是一个面向国产异构架构设计的高性能推理引擎。在架构设计上,上层提供 API Server 和 Web Server,支持 OpenAI 兼容接口。核心引擎部分包括异步推理框架,负责请求调度、缓存管理和推理阶段调度。Batch Manager 管理批处理, Scheduler 进行任务调度,Model Executor 执行 Prefill、Decoding 和 Sample 等推理阶段。
SigInfer 是一个面向国产异构架构设计的高性能推理引擎。在架构设计上,上层提供 API Server 和 Web Server,支持 OpenAI 兼容接口。核心引擎部分包括异步推理框架,负责请求调度、缓存管理和推理阶段调度。Batch Manager 管理批处理, Scheduler 进行任务调度,Model Executor 执行 Prefill、Decoding 和 Sample 等推理阶段。SigInfer 的关键创新在于异构抽象层的设计。这一层包括三个核心组件。xcore-ops 是跨平台推理算子库,提供平台统一的算子接口。xcore-rt 是跨平台运行时库,提供平台统一的运行时管理接口。xcore-xccl 是跨平台通信库,提供平台统一的设备通信接口。通过这一抽象层,SigInfer 实现了对多种国产加速器的广泛适配,同时保持了上层代码的统一性。
19交互墙问题的实际表现

在 DeepSeek-V3-W8A8 单请求性能分析中发现了严重的交互墙问题。多数 Host 任务的执行时间远超 Device 任务的执行时间,甚至 Launch 时间也要大于 Device 的实际执行时间。特别是 hcom_allReduce 和 hcom_allGather 这两个通信操作的 Host 开销极大。在 allReduce 执行时,Device 基本处于空闲状态,而在 allGather 执行时虽然还有一些算子在运行,但也无法填满 Device。这种现象说明交互开销已经严重制约了整体性能的发挥。
20超越图模式的优化思路 图模式 Graph Mode 是业界解决算子下发开销的主流方案,但它存在一些固有缺陷。首先是额外的内存占用,以 DeepSeek 场景为例,使用 torchair 在昇腾上需要 1.2GB 额外内存,vLLM 在 NVIDIA 上需要 1 到 3GB,这对内存受限场景影响很大。其次是不够灵活,图结构容易因为动态性而 break。第三是需要算子特殊适配,像 torchair 这样的实现中,部分高性能算子难以直接利用。
图模式 Graph Mode 是业界解决算子下发开销的主流方案,但它存在一些固有缺陷。首先是额外的内存占用,以 DeepSeek 场景为例,使用 torchair 在昇腾上需要 1.2GB 额外内存,vLLM 在 NVIDIA 上需要 1 到 3GB,这对内存受限场景影响很大。其次是不够灵活,图结构容易因为动态性而 break。第三是需要算子特殊适配,像 torchair 这样的实现中,部分高性能算子难以直接利用。基于这些问题,需要探索图模式以外的解决方案。新方案的优势在于三个方面。第一是无额外的内存占用,对于内存受限场景如单机跑 DeepSeek 这样的大模型有重要意义。第二是更加灵活,不需要复杂的图相关操作。第三是具有良好的算子兼容性,可以无缝兼容现有算子库,充分利用已有的优化成果。
21算子下发流程的深入解析
 CPU 到加速器的完整任务下发流程可以分为四个阶段。第一阶段是算子库准备操作,在 CPU 上执行参数准备和初始化工作。第二阶段是命令下发操作,同样在 CPU 上执行,Runtime 或 Driver 将任务信息写入命令队列。第三阶段是算子在加速器上的实际执行,时间取决于计算负载。第四阶段是中断处理,在 CPU 上执行完成通知和后续处理。
CPU 到加速器的完整任务下发流程可以分为四个阶段。第一阶段是算子库准备操作,在 CPU 上执行参数准备和初始化工作。第二阶段是命令下发操作,同样在 CPU 上执行,Runtime 或 Driver 将任务信息写入命令队列。第三阶段是算子在加速器上的实际执行,时间取决于计算负载。第四阶段是中断处理,在 CPU 上执行完成通知和后续处理。以 AMD GPU 的 ROCm 为例,它采用 UMD 驱动的低延迟下发机制。主机侧进行参数准备耗时约 0.7 微秒,向命令队列写入任务包耗时约 1.9 微秒。设备侧接收任务后开始执行,完成后将中断原因写入环形缓冲区并触发中断通知主机侧。这种设计的优势在于主机侧可以在用户态直接向命令队列提交任务,内核部分相对简单,对 CPU 的负担较小,从而实现了更低的交互延迟。
22线程隔离优化 CPU 负载
 通过对 CPU 任务负载的深入检测,发现了两个影响性能的关键现象。第一个是内核算子下发线程占用 CPU 资源过高,第二个是 IRQ 中断处理导致性能不稳定。针对这些问题,提出了线程隔离的优化方案。
通过对 CPU 任务负载的深入检测,发现了两个影响性能的关键现象。第一个是内核算子下发线程占用 CPU 资源过高,第二个是 IRQ 中断处理导致性能不稳定。针对这些问题,提出了线程隔离的优化方案。具体措施包括三个方面。首先对任务下发相关的线程进行强制的 CPU 亲和性设定,将它们绑定到特定的 CPU 核心上,避免单一 CPU 负载过重。其次关闭系统的 IRQ Balance 功能,防止中断在不同核心间迁移。第三是对中断处理函数也进行 CPU 亲和性设定,使其运行在专门的核心上,避免干扰主要的推理线程。通过这些措施,可以有效降低线程竞争和上下文切换的开销。
23算子库准备操作的并行化 针对昇腾算子库准备操作流程的深入分析,提出了一种更加轻量化的并行优化方案。核心思路是提升 CPU 的并行度,从单一 CPU 负载模式改为任务并发模式。具体实现上,在 CPU 端引入多线程,每个线程绑定一个 NPU stream,避免单一 stream 导致的资源竞争。
针对昇腾算子库准备操作流程的深入分析,提出了一种更加轻量化的并行优化方案。核心思路是提升 CPU 的并行度,从单一 CPU 负载模式改为任务并发模式。具体实现上,在 CPU 端引入多线程,每个线程绑定一个 NPU stream,避免单一 stream 导致的资源竞争。为了实现多 stream 间的任务同步,引入了 Notify 机制。Notify 是 NPU 上的一种轻量级同步机制,类似于二值信号量。关键特点是 set 和 wait 操作不会阻塞 CPU 线程的执行,只会阻塞 NPU stream。这样既保证了算子执行顺序的正确性,又避免了 CPU 的空转等待。这种设计借鉴了 CUDA Graph 的思想,假设算子调用不依赖 CPU 状态,这一假设在大模型推理中基本成立。Thread0 作为主线程负责派发算子下发任务给其他子线程,形成了高效的并行执行模式。
24优化效果的逐步提升 通过一系列优化措施,NPU 的空闲时间逐步减小,整体性能持续提升。从基线版本开始,可以看到明显的 NPU 空闲时间。通过隔离中断线程,获得了初步改善。进一步将通信任务单独绑定到专门的线程,性能继续优化。采用 1 个 worker 线程加 1 个 hccl 通信线程的配置,实现了显著提升。继续增加到 2 个 worker 线程配合 1 个 hccl 线程,性能持续改进。最终使用 3 个 worker 线程配合 1 个 hccl 线程,接近了最优配置。
通过一系列优化措施,NPU 的空闲时间逐步减小,整体性能持续提升。从基线版本开始,可以看到明显的 NPU 空闲时间。通过隔离中断线程,获得了初步改善。进一步将通信任务单独绑定到专门的线程,性能继续优化。采用 1 个 worker 线程加 1 个 hccl 通信线程的配置,实现了显著提升。继续增加到 2 个 worker 线程配合 1 个 hccl 线程,性能持续改进。最终使用 3 个 worker 线程配合 1 个 hccl 线程,接近了最优配置。Profiler 的分析数据显示,通过多线程并发和线程隔离的组合优化,成功让 NPU 保持了更高的负载状态,交互墙问题得到了有效缓解。这一系列优化充分说明,通过精细的系统调优,可以显著提升国产加速器的实际性能表现。
25总结与展望大模型推理的性能优化是一项系统工程,需要从算法、算子、系统、硬件多个层面协同设计。在算子层面,需要持续优化矩阵乘法、Attention 等核心算子,适应动态形状场景的挑战。在系统层面,需要打破交互墙,通过多线程、异步执行、线程隔离等技术手段提升加速器的利用率。在架构层面,需要根据具体场景合理选择并行策略,平衡计算、通信、存储之间的关系。在工程层面,需要构建统一的异构抽象层,支持多样化的硬件架构。
SigInfer 推理引擎在国产架构适配方面的实践表明,通过全栈优化,国产加速器同样可以达到业界先进水平。未来随着模型规模继续扩大、上下文长度持续增长、稀疏专家混合等新架构的出现,系统优化将面临更多挑战,也孕育着更多创新机会。从性能工程的视角来看,只有深入理解硬件特性、充分利用系统资源、精心设计优化策略,才能真正发挥大模型的潜力,为用户提供高效、稳定、低成本的推理服务。
以上就是本次分享的内容,谢谢大家。
转载请注明来自海坡下载,本文标题:《系统与设计系统的优化(面向大模型推理的模型与系统协同优化)》
 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...